When to use Clustering OR Partitioning OR Both
1. Partition only
Need of strict cost guarantees before running a query
in a single partition all the related data that belongs to that partition is stored.
For example, a partition of today’s date will contain only today’s data, nothing else. In a query using WHERE data = .. BigQuery will know where to go.
Need to handle/manage table at partition-level for expirations, DML ops...
You can set expiration time to single partitions and not the entire table.
2. Partition and Clustering
No need of of strict cost guarantees before running a query
using the WHERE clause and using partitions optimized on it,
When we go into the buckets. It can contain multiple values, so the entire bucket must be processed
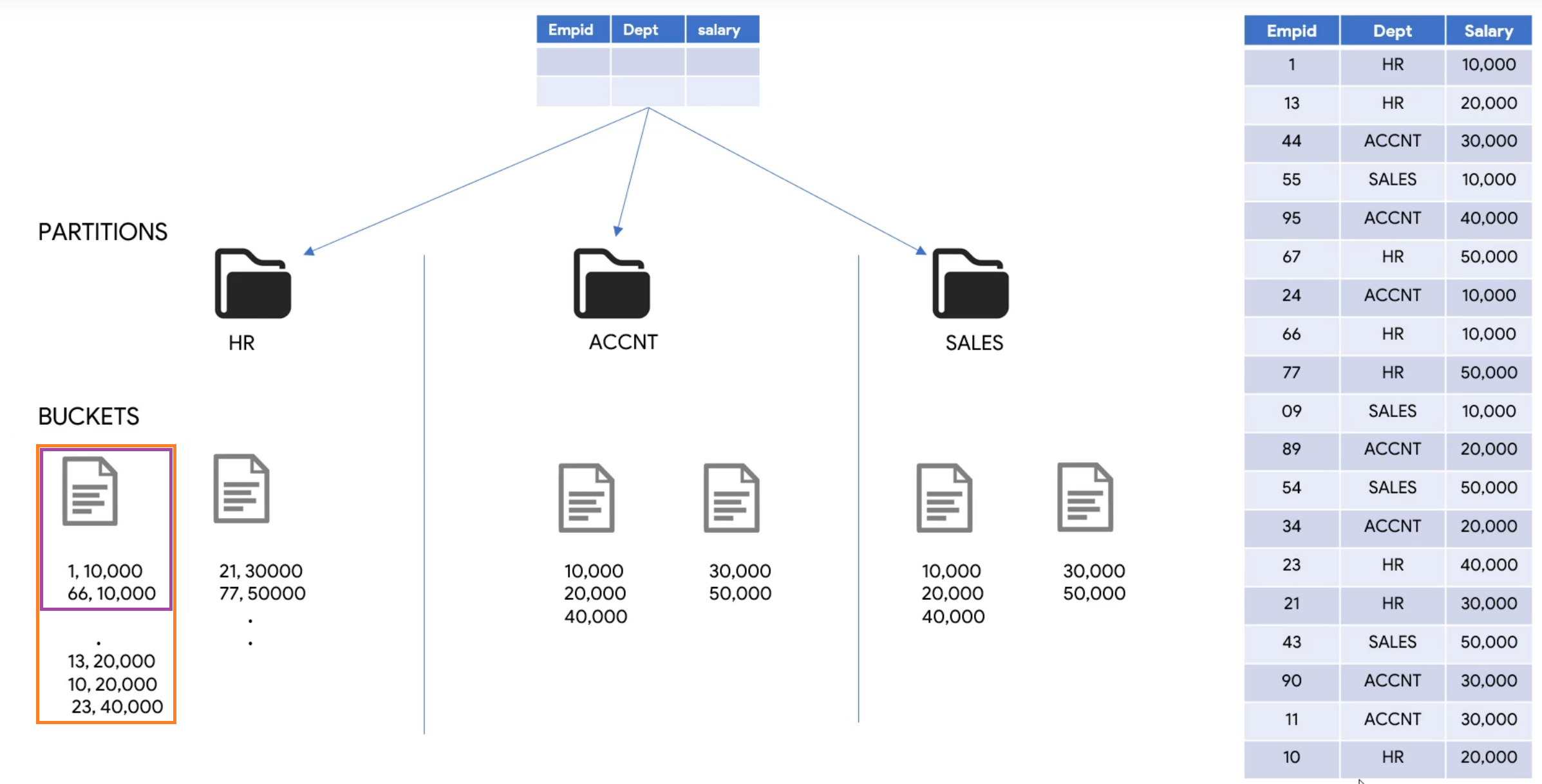
Data is huge within partition
Using frequend filter and aggregate queries on table
BigQuery automatically sorts data in a table based on clustering columns
3. Clustering only
Data is unique
And partition would create a large number of partitions (thousands). Here clustering is better.